

YLearn 因果模型包含三个部分内容:
CausalGraph 表示变量间的因果结构;CausalModel 来识别因果量;Probability。在具体介绍之前,首先了解一些因果结构和有向无环图(DAG)的知识。变量集 $V$ 的因果结构 能够被一个有向无环图来表示,其中 DAG 中每个节点对应于 $V$ 中的一个变量;变量间的直接函数关系由DAG中的一个带箭头的连接线表示。用 DAG 表示的因果结构能够精确地说明每一个变量是如何被它的父节点影响的。举个例子, $X \leftarrow W \rightarrow Y$ 表明 $W$ 是一个父节点,也是变量 $X$ 和 $Y$ 共同的因。更具体一点,有两个不同的变量 $V_i$ 和 $V_j$,如果它们的函数关系是
$$V_j = f(V_i, \eta_{ij})$$
其中,$f$ 为函数关系,$\eta$表示噪声。那么用 DAG 来表示这个因果结构时,应该有一个箭头从 $V_i$ 指向 $V_j$。了解更多关于DAGs和因果结构的信息,可以参考 Pearl。
根据 Pearl 的理论,因果效应(也称因果估计量)能够用 $do$ 算子来表示。例如表达式:
$$P(y|do(x))$$
代表在施加干预 $x$ 后 $y$ 的概率函数。因果结构对于表达和估计感兴趣的因果估计量至关重要。YLearn实现了一个对象 CausalGraph 来表示因果结构及对因果结构做一些操作。具体请参考 CausalGraph。
YLearn 关注因果推断和机器学习的交叉应用,因此我们假设使用的数据是足够多的观测数据,而不是需要设计随机实验得到的实验数据。对于一个表示因果结构的DAG,因果估计量通常不能被直接的从数据中估计出来,(如平均治疗效应(ATEs))。因为反事实结果是不能够被观测到的。因此有必要在进行任何估计之前,将这些因果估计量转化为其他的能够从数据中估计出来的量,它们被称为统计估计量。把因果估计量转化为对应的统计估计量的过程称为识别。
支持识别和其他因果结构相关操作的对象 CausalModel。具体请参考 CausalModel。
在Pearl的因果推断语言中,经常把结果表示为概率的形式。为了方便表示,YLearn实现了一个名为 Prob 的对象,具体请参考 Probability。
这是一个表示因果结构的DAGs的类。
通常来说,对于一组变量 $V$ ,如果 $V_j$ 能够对应于 $V_i$ 的变化而变化,那么变量 $V_i$ 被称为变量 $V_j$ 的因。在 一个因果结构的DAG中,每个父节点都是它所有的孩子的直接的因。我们把这些因果结构的DAGs称为因果图。对于图的术语,举个例子,可以参考 Pearl 的Chapter 1.2。
有五个基本的由两到三个节点组成的结构用于构建因果图。除了这些结构,还有用概率的语言描述的在因果图中的关联和因果关系的流。任意两个节点 $X$ 和 $Y$ ,如果被关联流连接在一起,则表示它们是统计不独立的。等价于 $P(X, Y) \neq P(X)P(Y)$ 。令 $X, Y$ 和 $W$ 为三个不同的节点,那么五个基本的结构包括:
$$X \rightarrow W \rightarrow Y,$$
$X$ 和 $Y$ 是统计不独立的;
$$X \leftarrow W \rightarrow Y,$$
$X$ 和 $Y$ 是统计不独立的;
$$X \rightarrow W \leftarrow Y,$$
$X$ 和 $Y$ 是统计独立的;
$$X \quad Y,$$
$X$ 和 $Y$ 是统计独立的;
$$X \rightarrow Y,$$
$X$ 和 $Y$ 是统计不独立的。
在YLearn中,使用CausalGraph类来表示因果结构,首先给一个python的字典,其中每个键都是它对应的通常由字符串的列表表示的值的每个元素的子节点。
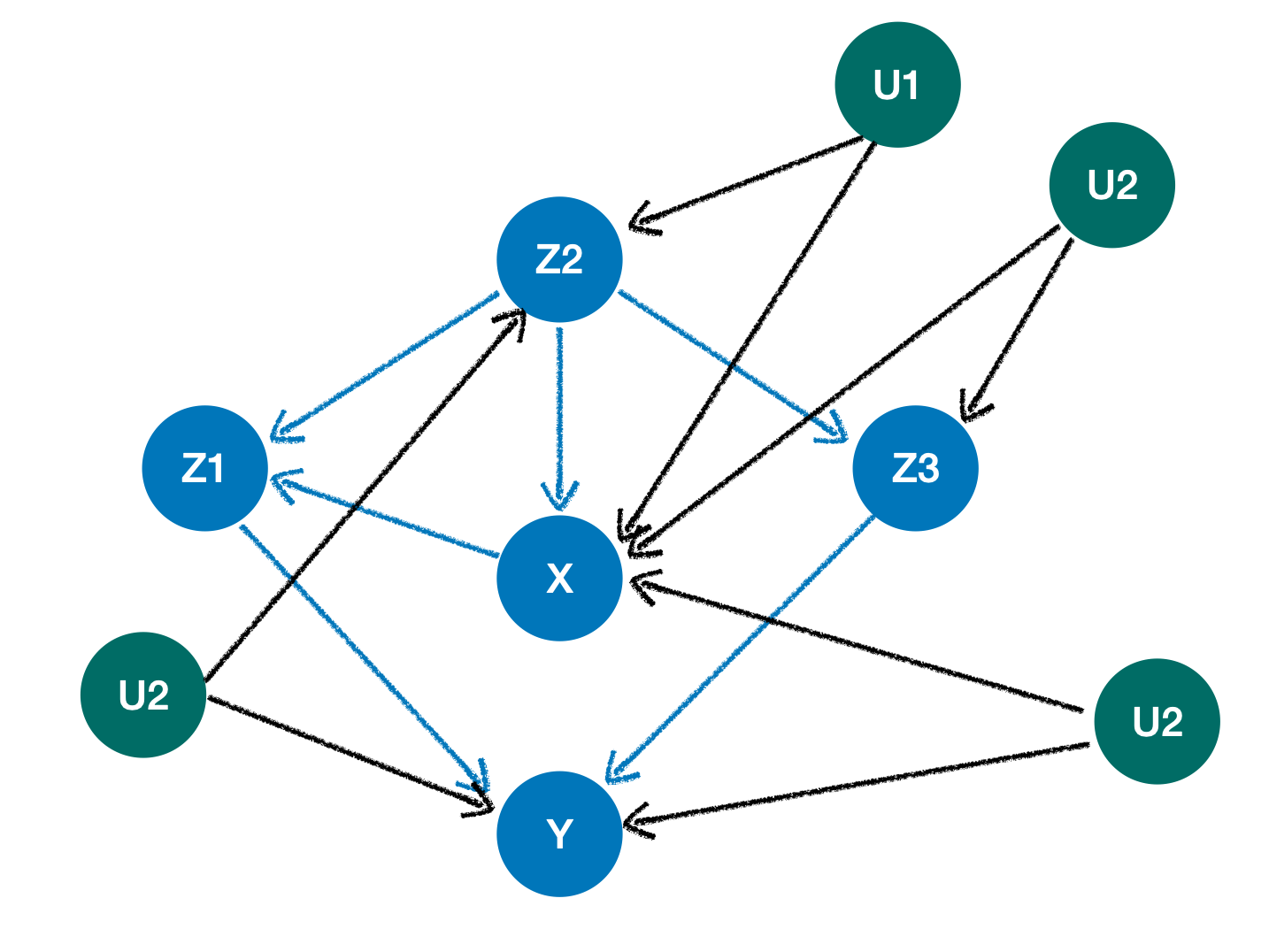
因果结构,其中所有的绿色节点都是未观察到的(一个变量是未观察到的如果它没有显示在数据集中但是可以相信它与其他变量有因果关系)。
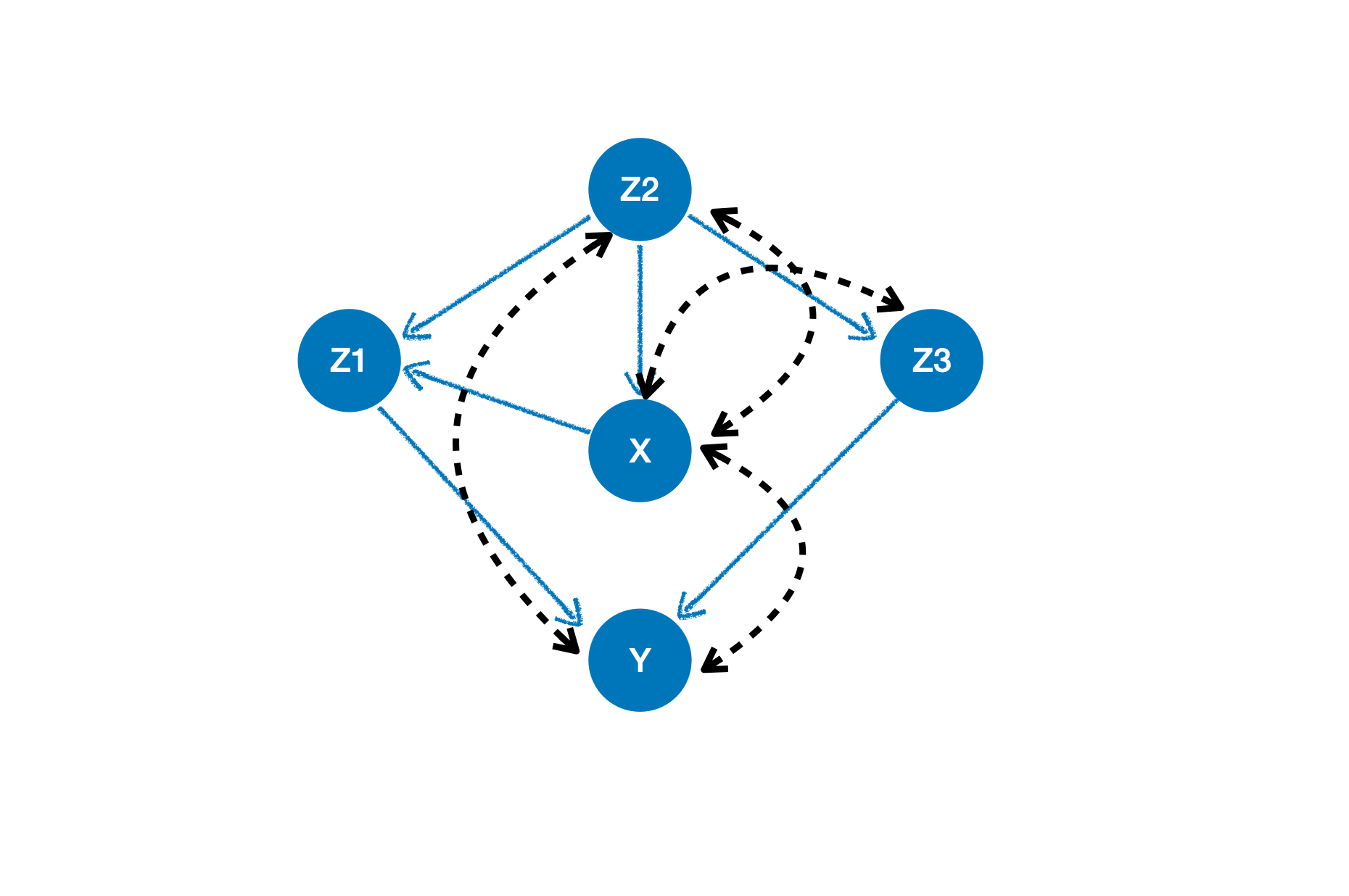
因果结构,其中所有的未观察到的变量都被移除了,它们相关的因果关系都被混淆的弧线(有两个箭头的黑色虚线)取代了。
我们可以像下面那样用YLearn表示这个因果结构:
from ylearn.causal_model.graph import CausalGraph
causation = {
'X': ['Z2'],
'Z1': ['X', 'Z2'],
'Y': ['Z1', 'Z3'],
'Z3': ['Z2'],
'Z2': [],
}
arcs = [('X', 'Z2'), ('X', 'Z3'), ('X', 'Y'), ('Z2', 'Y')]
cg = CausalGraph(causation=causation, latent_confounding_arcs=arcs)
list(cg.c_components)
>>> [{'X', 'Y', 'Z2', 'Z3'}, {'Z1'}]
CausalModel 类是一个执行识别 identification 和寻找工具变量的核心对象。
在介绍因果模型之前,我们首先需要阐明 干涉 的定义。干涉是对整个人群的,并给每一个人一些操作。 [Pearl]_ 定义了 $do$-operator 来描述了这样的操作。概率模型不能够服务预测干涉效果,这导致了对因果模型的需求。
对 causal model 的正式定义来自 Pearl 。一个因果模型是一个三元组
$$ M = \left< U, V, F\right> $$
其中
$$ V_i = F_i(pa_i, U_i)$$
其中 $pa_i \subset V \backslash V_i$.
例如, $M = \left< U, V, F\right>$ 是一个因果模型其中
$$ V = {V_1, V_2}, $$ $$ U = { U_1, U_2, I, J},$$ $$ F = {F_1, F_2 } $$
这样
$$V_1 = F_1(I, U_1) = \theta_1 I + U_1 $$ $$V_2 = F_2(V_1, J, U_2, ) = \phi V_1 + \theta_2 J + U_2.$$
注意每个因果模型都可以和一个DAG关联并编码变量之间必要的因果关系信息。
YLearn使用 CausalModel 来表示一个因果模型并支持许多关于因果模型的操作比如 identification 。
为了表征干涉的效果,需要考虑 因果效应 ,其是一个因果估计量包含 $do$-operator 。把因果效应转变为对应的统计估计量的行为被称为 :ref:identification 且
在YLearn中的 CausalModel 里实现。注意不是所有的因果效应都能被转变为统计估计量的。我们把这样的因果效应称为不可识别的。我们列出几个 CausalModel 支持的识别方法。
$X$ 对 $Y$ 的因果效应由下式给出
$$P(y|do(x)) = \sum_w P(y|x, w)P(w)$$
如果变量的集合 $W$ 满足后门准则关于 $(X, Y)$.
$X$ 对 $Y$ 的因果效应由下式给出
$$P(y|do(x)) = \sum_w P(w|x) \sum_{x’}P(y|x’, w)P(x’)$$
如果变量的集合 $W$ 满足前门准则关于$(X, Y)$ and if $P(x, w) > 0$.
[Shpitser2006]_ 给出一个必要充分的图的条件这样任意一个集合的变量对另一个任意集合的因果效应能够被唯一的识别无论它是不是可识别的。 我们称验证这个条件对应的行动为 通用识别。
当有未观测到的 $X$ 和 $Y$ 的混淆因素时,工具变量在识别和估计 $X$ 对 $Y$ 的因果效应很有用处。 一组变量 $z$ 被称为一组 工具变量 如果 $z$ 中任意的 $z$ :
$z$ 对 $X$ 有因果效应。
$z$ 对 $Y$ 的因果效应完全由于 $X$ 。
没有后门路径从 $z$ 到 $Y$ 。
因果结构,其中所有的未观察到的变量都被移除了,它们相关的因果关系都被混淆的弧线(有两个箭头的黑色虚线)取代了。
对于图中的因果结构,我们想要使用 通用识别 方法识别 $X$ 对 $Y$ 的因果效应。第一步是用 CausalModel 表示因果结构。
from ylearn.causal_model.graph import CausalGraph
causation = {
'X': ['Z2'],
'Z1': ['X', 'Z2'],
'Y': ['Z1', 'Z3'],
'Z3': ['Z2'],
'Z2': [],
}
arcs = [('X', 'Z2'), ('X', 'Z3'), ('X', 'Y'), ('Z2', 'Y')]
cg = CausalGraph(causation=causation, latent_confounding_arcs=arcs)
然后我们需要为编码在 cg 中的因果结构定义一个 CausalModel 的实例,从而进行识别。
from ylearn.causal_model.model import CausalModel
cm = CausalModel(causal_model=cg)
stat_estimand = cm.id(y={'Y'}, x={'X'})
stat_estimand.show_latex_expression()
>>> \sum_{Z3, Z1, Z2}[P(Z2)P(Y|Z3, Z2)][P(Z1|Z2, X)][P(Z3|Z2)]
结果是想要的识别的在给定的因果结构中 $X$ 对 $Y$ 的因果效应。
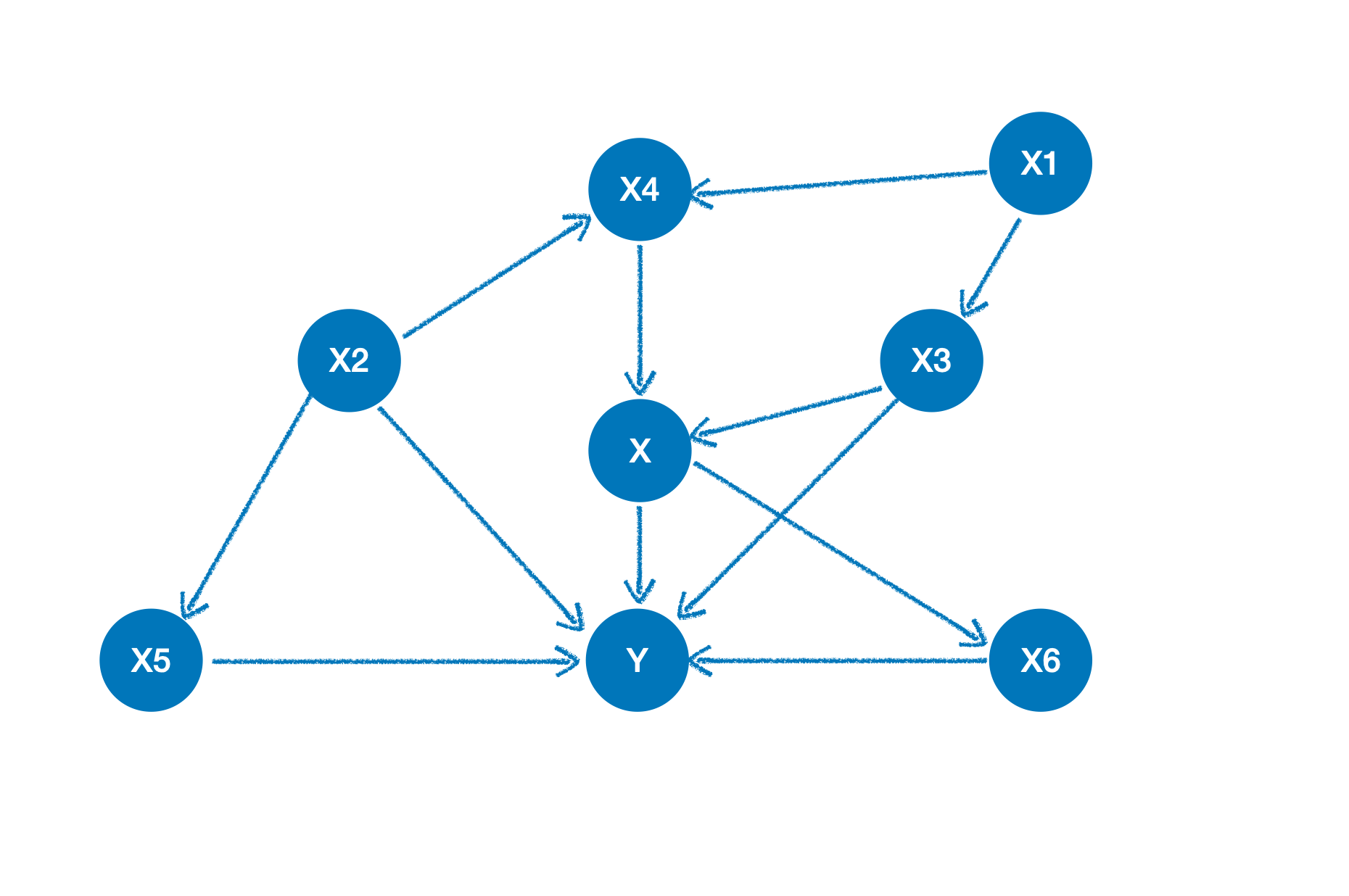
所有节点都是观测到的变量。
对于图中的因果结构,我们想要使用 后门调整 方法识别 $X$ 对 $Y$ 的因果效应。
from ylearn.causal_model.graph import CausalGraph
from ylearn.causal_model.model import CausalModel
causation = {
'X1': [],
'X2': [],
'X3': ['X1'],
'X4': ['X1', 'X2'],
'X5': ['X2'],
'X6': ['X'],
'X': ['X3', 'X4'],
'Y': ['X6', 'X4', 'X5', 'X'],
}
cg = CausalGraph(causation=causation)
cm = CausalModel(causal_graph=cg)
backdoor_set, prob = cm3.identify(treatment={'X'}, outcome={'Y'}, identify_method=('backdoor', 'simple'))['backdoor']
print(backdoor_set)
>>> ['X3', 'X4']
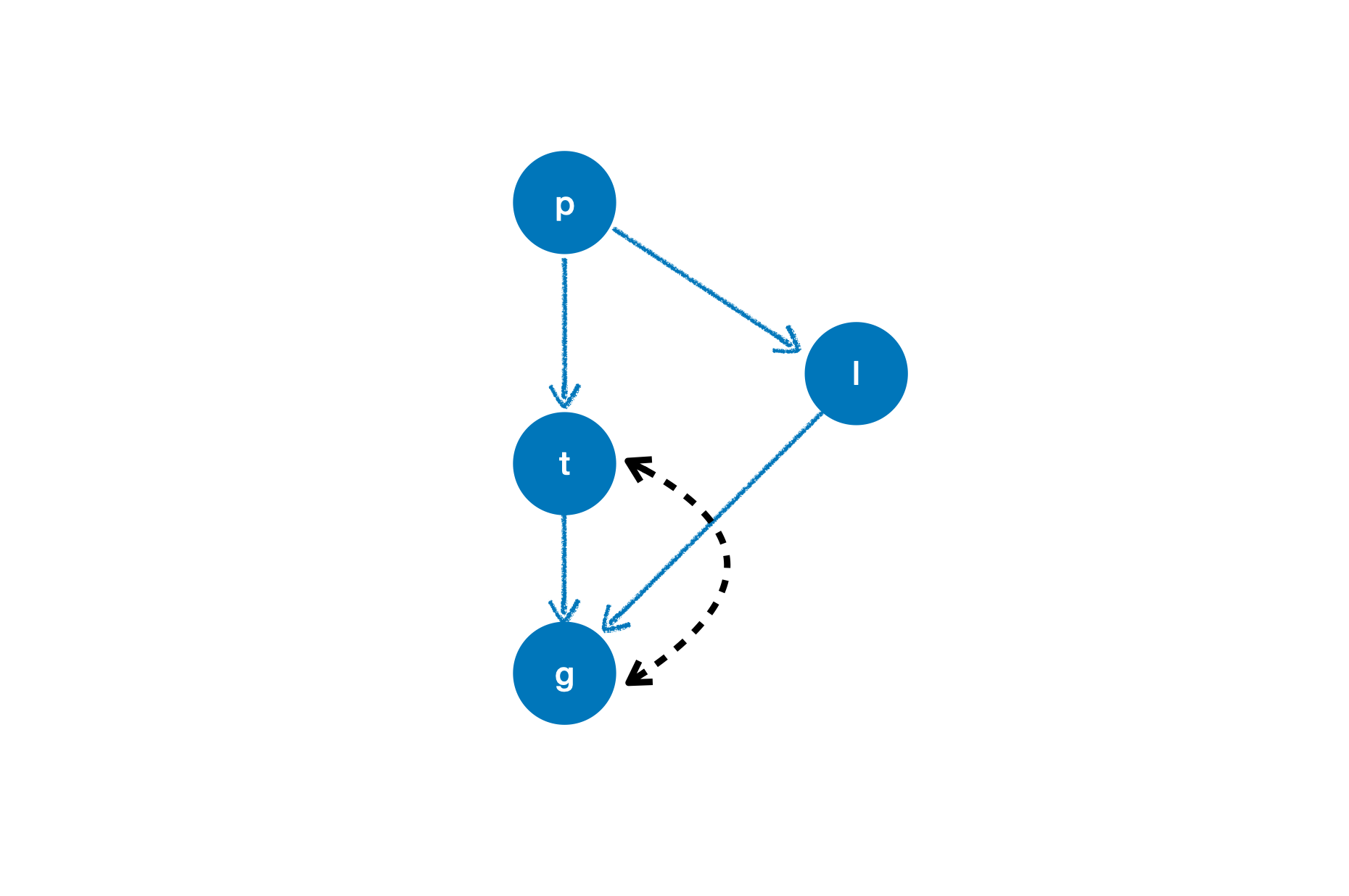
变量 p, t, l, g 的因果结构
我们想要为 t 对 g 的因果效应找到合理的工具变量。
causation = {
'p':[],
't': ['p'],
'l': ['p'],
'g': ['t', 'l']
}
arc = [('t', 'g')]
cg = CausalGraph(causation=causation, latent_confounding_arcs=arc)
cm = CausalModel(causal_graph=cg)
cm.get_iv('t', 'g')
>>> No valid instrument variable has been found.
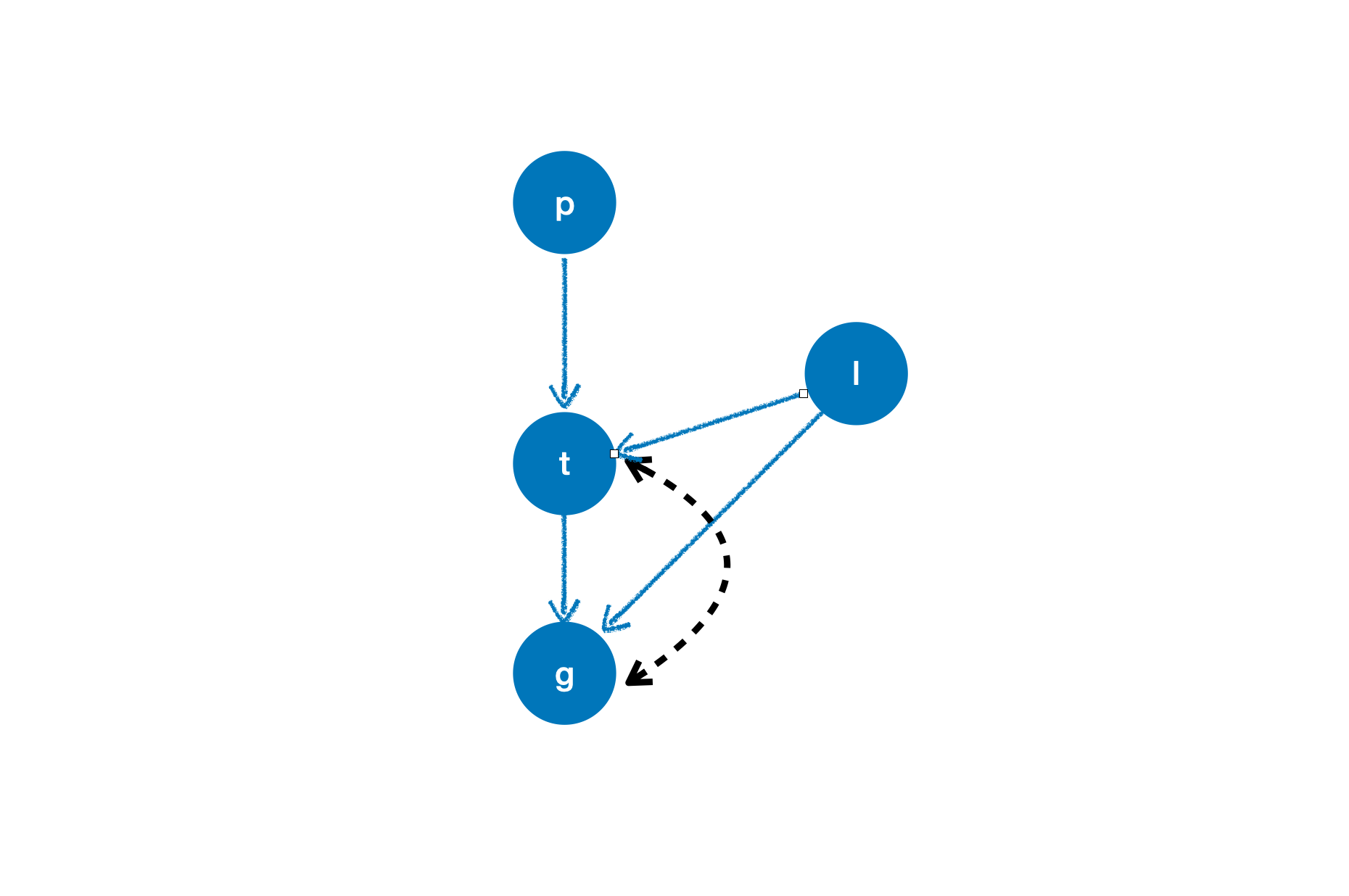
对变量 p, t, l, g 的另一个因果结构
我们依然想要在这个新的因果结构中,为 t 对 g 的因果效应找到合理的工具变量。
causation = {
'p':[],
't': ['p', 'l'],
'l': [],
'g': ['t', 'l']
}
arc = [('t', 'g')]
cg = CausalGraph(causation=causation, latent_confounding_arcs=arc)
cm = CausalModel(causal_graph=cg)
cm.get_iv('t', 'g')
>>> {'p'}
YLearn能够输出和修改类似如下的概率表达式:
$$ P(x, y|z),$$
用户能够定义一个Prob 的实例,以及改变它的属性.
如一个概率表达式:
$$ \sum_{w}P(v|y)[P(w|z)P(x|y)P(u)] $$
它由两个部分组成:一个条件概率$P(v|y)$ 和一个多概率的乘积 $P(w|z)P(x|y)P(u)$,然后这两个部分的积在给定的$W$ 下求和。
首先定义第一个条件概率$P(v|y)$ :
from ylearn.causal_model.prob import Prob
var = {'v'}
conditional = {'y'} # the conditional set
marginal = {'w'} # sum on w
然后, 继续定义第二个多条件概率的乘积 $P(w|z)P(x|y)P(u)$
p1 = Prob(variables={'w'}, conditional={'z'})
p2 = Prob(variables={'x'}, conditional={'y'})
p3 = Prob(variables={'u'})
product = {p1, p2, p3}
最终的结果可以表示为:
P = Prob(variables=var, conditional=conditional, marginal=marginal, product=product)
P.show_latex_expression()
>>> `\sum_w P(v|y)[P(u)][P(w|z)][P(x|y)]`
Prob类的实例还可以输出LaTex代码:
P.parse()
>>> '\\sum_{w}P(v|y)\\left[P(u)\\right]\\left[P(w|z)\\right]\\left[P(x|y)\\right]'