

YLearn,是"Learn Why"(学习为什么)的双关语,是唯一一款能够独立完成端到端、全流程解决 “因果发现、因果量识别、因果效应估计、反事实推断和策略学习” 五个因果学习任务的开源算法工具包。YLearn 还提供了一个高层级的 API,可以降低整个工具的使用门槛。
一个典型的完整因果推断流程主要由三个步骤组成。第一,通过算法等手段学习和发现数据中的因果结构,这一过程通常被称为因果发现(causal discovery)。被发现的因果结构或关系则被表示为因果结构公式(structural causal models, SCM)或因果图(一种有向无环图,directed acyclic graphs, DAG)。第二,选择因果问题中我们感兴趣的的变量,并用因果变量(causal estimand)表示,例如平均治疗效应(average treatment effect, ATE)。因为因果变量无法从数据中直接估计,所以因果变量会通过因果效应识别这一过程转化为统计变量(statistical estimand)。识别后的因果变量则可以从数据中被估计出来。第三,选择合适的因果估计模型从数据中去学些这些被识别后的因果变量,得到感兴趣的因果效应估计。之后,可进一步解决策略估计问题和反事实问题等因果问题。
YLearn 致力于在机器学习的帮助下支持因果推断从因果发现到因果效应估计过程中各方面的相关内容,实现了多个近期技术文献发展出的因果推断相关算法。对于有大量观测数据的实验,得到了令人鼓舞的结果。
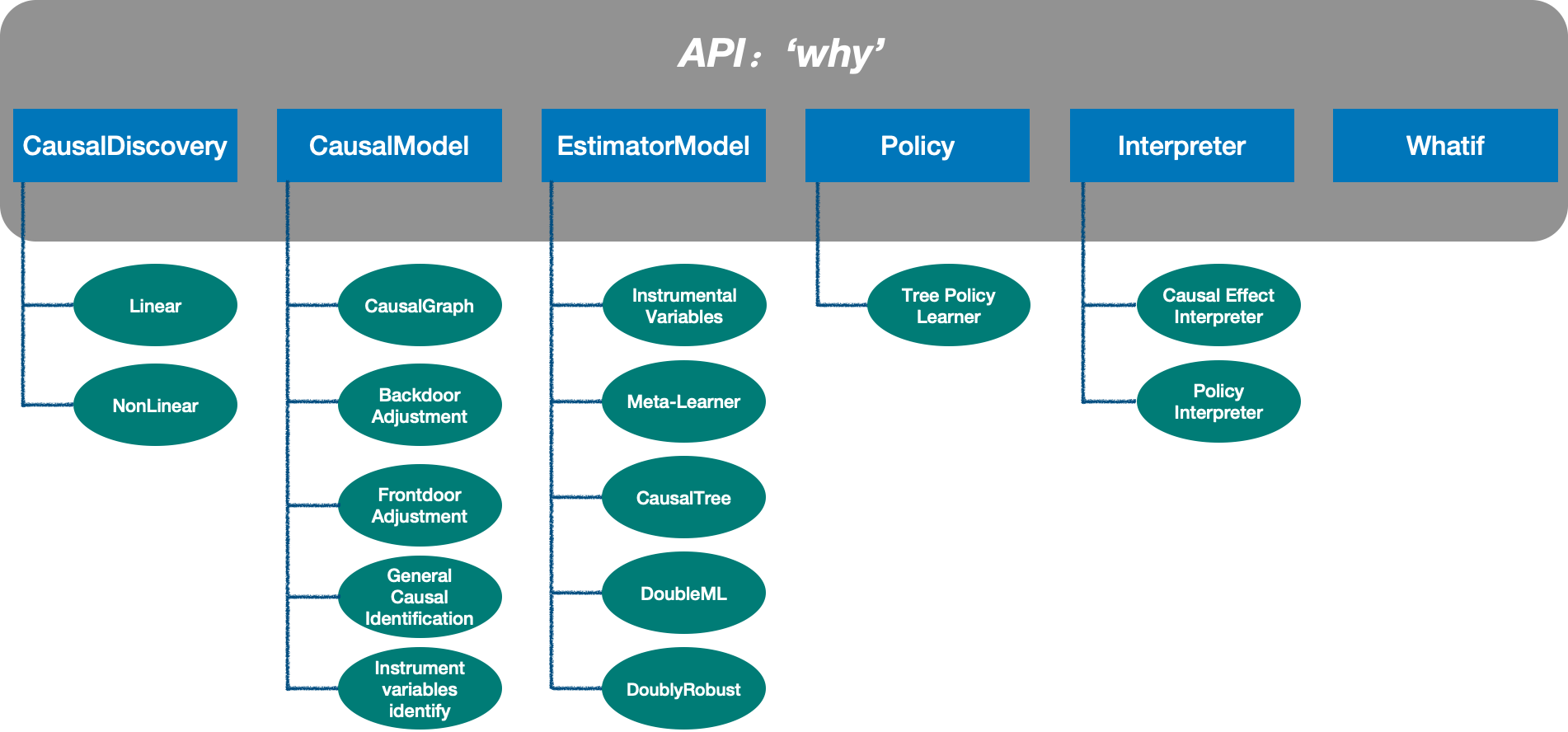
YLearn 按照因果推断流程和因果推断任务,分成了5个主要模块。他们的功能描述为:
CausalGraph表示因果结构和因果关系,并依靠CausalModel实现不同的因果操作(如因果效应识别)通过组合使用以上不同模块,可以完成一个完整的因果学习流程。此外,YLearn 将这些模块封装成一个统一的 API 接口 Why,提供了另一种更简便的使用方法。
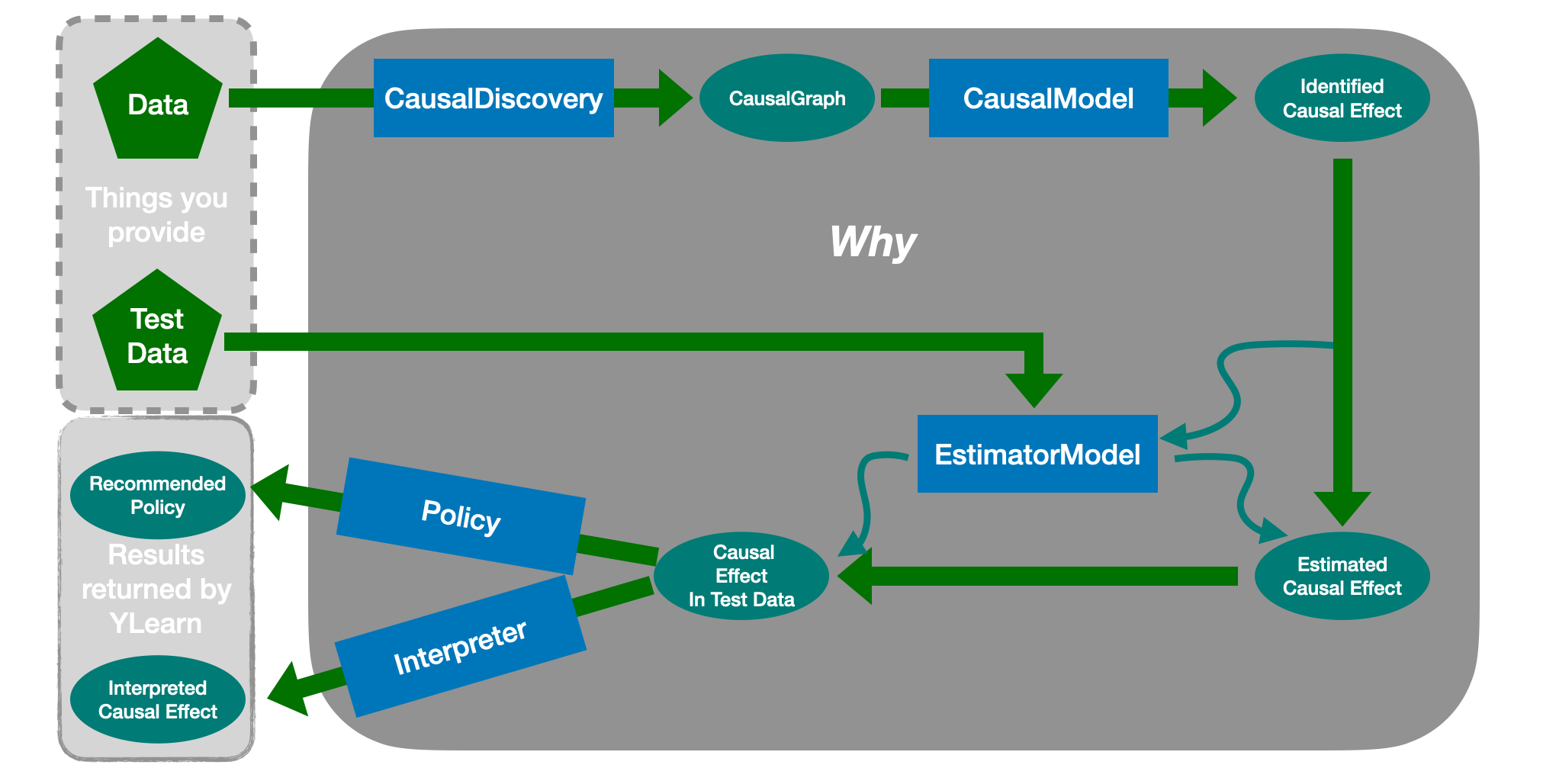
上图展示了使用 YLearn 完成因果推断任务的完整流程。从用户给定的训练数据开始,我们首先:
CausalDiscovery 去发现数据中的因果关系和因果结构,通常输出一个 CausalGraph (因果图)。CausalModel中。同时,用户感兴趣的因果变量在CausalModel中会通过因果效应识别转化为相应的可被估计的统计变量(也叫识别后的因果变量)。EstimatorModel中某个(些)特定的模型会在训练集中训练,得到最优的估计模型,可以从数据中估计识别后的因果变量。